controller/ daemonSet & statefulSet
## 마스터노드 - 워커노드 커넥션 연동&해제하기
# 마스터 노드 - 워커 노드를 연결을 끊는 방법부터 알아보자.
master node에서 먼저 node를 제거해줘야 한다.
kubectl get nodes
난 현재 worker1, worker2 이렇게 두 워커 노드가 있다.
여기서 worker1 node를 삭제해보겠다. 삭제하기전에 node1에서 작동중인 pod가 있는지를 체크하고 삭제하자.
kubectl delete nodes worker1
삭제 후에 해당 워커노드 vm으로 가서,
kubeadm reset명령어를 치면 master node와의 행복한 기억들을 모두 지워준다.
중간에 y까지 치고 동의하면,
뭐가 뜨는데 잘된건진 모르곘다. 이후에 join을 쳤을때 안되면 잘안된거다.
# master node에서 새로운 token을 만들기.
kubeadm token create --print-join-command이렇게 master노드에서 새로운 토큰을 만들고 join명령어까지 출력해달라고 하자.
--ttl옵션으로 토큰 유효기간도 설정가능.

만들어졌고 저 join 명령어는 메모장에 복사해두자.
kubeadm token list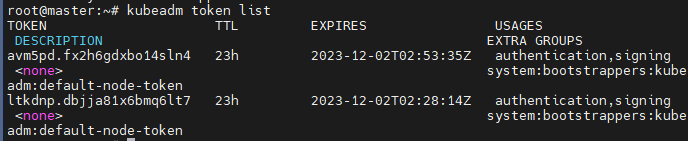
현재 만들어진 토큰들을 볼 수 있다.
# worker node에서 master node에 join시키기
아까 메모장에 복사해둔 명령어를 worker node에서 입력하면,

잘 join됐다고 답장을 받았다.
그리고 master node에서
kubectl get nodes명령어를 치면

워커노드 1이 잘 쪼인 되었다.
++ 파드를 만들고 컨테이너가 creating 상태에서 멈췄다.
뭣때문인지 모르겠는데 worker1에 생성된 pod를 describe로 보니 에러메세지에 cni0인터페이스의 아이피가 안맞는다고 떴다.
worker1노드에서 kubeadm reset후, 노드를 재부팅
이후
swapoff -akubeadm join 211.183.3.10:6443 --token avm5pd.fx2h6gdxbo14sln4 --discovery-token-cash sha256:2cf79d30deb17c3d128127dd8fe73796225dc60a462b9b5bb7cc324ed59b22f8아랫 명령어로 다시 쪼인시켜보자.
ㅠㅠ
## daemonSet
# 컨트롤러 개념
위에서 워커노드를 제거하고 다시 연결하는걸 설명한 이유는 이 컨트롤러 때문이다.
daemonSet 컨트롤러는 노드당 하나의 파드를 보장을 해준다. 때문에 노드가 한개면 파드도 한개, 노드가 두개면 노드도 두개 등등으로 동작을 한다. 이 것을 실험하기 위해선 노드 갯수를 조절해야 하기 때문에 앞서서 node의 연결을 끊고 join하는 방법부터 살펴본 것이다.
# 다른 컨트롤러와 비교
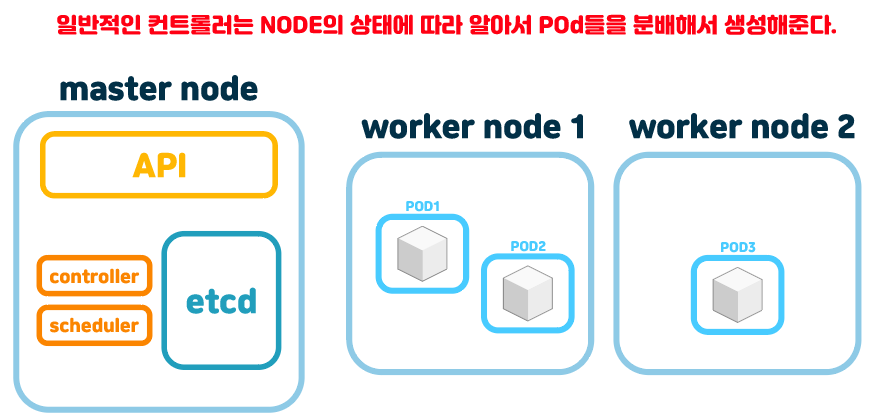
이렇게 우리가 사용해봤던 일반적인 컨트롤러들은 node1 node2에 상황에따라 적절히 pod들을 분배해서 생성해준다.
하지만 daemonSet은 노드당 하나의 파드를 만들어주는 컨트롤러다. 아래 그림과 같다.
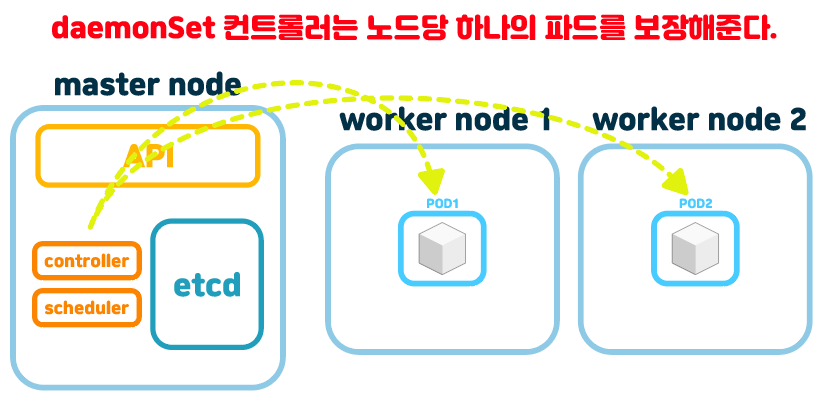
daemonSet pod는 우리가 만들어봤던 controller의 yaml 양식에서 replicas 키가 없다. 애초에 노드당 하나의 pod를 만들어주는거라서 갯수를 정해줄 필요가 없다.

이렇게 그림처럼 만약에 node가 하나 추가되면 daemonSet 컨트롤러는 이 node3에 새로운 pod를 자동으로 하나 생성해준다. 마찬가지로 지워질경우는 해당 노드의 pod를 없애준다.
# daemonSet 컨트롤러 yaml양식
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# these tolerations are to have the daemonset runnable on control plane nodes
# remove them if your control plane nodes should not run pods
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
# it may be desirable to set a high priority class to ensure that a DaemonSet Pod
# preempts running Pods
# priorityClassName: important
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log공식문서에서 따온 daemonSet 컨트롤러의 yaml양식인데 뭐 드럽게 길게 만들었다. 일단 자세히보면 우리가 일반적으로 썼던 다른 컨트롤러의 yaml양식에 있던 replicas라는 키가 없다. 어차피 노드수에 맞게 하나씩 pod를 생성해줄거라 필요가 없는거다.
또한 volume으로 마운트를 해줬는데 log라고 적혀있다. daemonSet 컨트롤러는 노드당 하나의 pod를 보장해주는데 이러한 설계는 로그를 쓰는데 자주 쓰여서 공식문서에서도 이렇게 log로 보여주나보다. 로그수집기나 클러스터 수집기, 모니터링같은 모든 노드에서 하나씩은 동작해야하는 pod컨테이너를 보통 daemonSet 컨트롤러로 관리한다고 한다.
daemonSet은 무조껀 노드당 해당 pod하나를 만들어주는데, 만약 두개를 만들고 싶으면 두 개의 daemonSet을 만들어야 한다.
# 실험해보기
직접 만들어보자.
공식문서에서 가져온 yaml양식으로 daemonSet 컨트롤러를 만들어 보았다.
kubectl create -f test-daem.yaml
현재 워커노드가 1,2 두개있으니 마스터노드까지 총 세 개의 pod가 만들어졌다.
이 상태에서 worker1노드를 하나 지워보자.
kubectl delete node worker1
성공적으로 지워졌다.
그리고 어느정도의 시간이 지난 후에

pod도 하나 지워졌다. NODE 컬럼을 보면 worker1에 있던 pod가 지워진걸 확인할 수 있다.
그럼 다시 worker1노드를 연결해보자.
아랫명령어는 worker1에서 치는거다.
kubeadm reset뭐 물어보면 y치고,
다시 마스터노드에 join시켜보자.
kubeadm join 211.183.3.10:6443 --token avm5pd.fx2h6gdxbo14sln4 --discovery-token-ca-cert-hash sha256:2cf79d30deb17c3d128127dd8fe73796225dc60a462b9b5bb7cc324ed59b22f8
다시 마스터 노드로 돌아와서
kubectl get nodes
잠시후에 마스터노드에서 worker1노드가 잡히게 되었다.
그리고 잠시후에 또

pod가 새로 생겼다.
++ 추가해서 daemonSet에도 rolling update, roll back 기능이 있다.
## statefulSet
#개념
얘는 pod의 이름을 보장해주는 컨트롤러다.
위에서 봤듯이 이것저것 컨트롤러를 만들떄는

이런식으로 해시가 붙는다.
하지만 statefulSet은 이 이름을 간결하게 커스텀 할 수 있고 0,1,2등으로 increasing방식으로 숫자가 붙는다.

요렇게 muzzi-0, muzzi-1, muzzi-2 식으로 이름이 정갈하고 깔끔하게 붙어서 pod들이 생성된다.
# yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: registry.k8s.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi얘도 daemonSet처럼 공식문서의 yaml형식은 드럽게 길다.
근데 특이하게 service도 같이 만든다. 난 아직 service는 안배웟기때문에 이건 생략하고
책에 있는 statefulSet양식을 가져와서 간결하게 테스트해볼 예정이다.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: muzzi
spec:
selector:
matchLabels:
app: nginx-statefulset
serviceName: "nginx-statefulset-service"
replicas: 3
template:
metadata:
labels:
app: nginx-statefulset
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx-statefulset
image: nginx
ports:
- containerPort: 80
name: webmetadate필드에 name필드에있는 muzzi스트링이 이 컨트롤러가 생성할 pod 이름이다.
이 muzzi에 -0, -1, -2등이 붙게 되는것이다.
또한 spec필드에 serviceName이라는 필드가 추가되는데 이건 아직 내가 서비스를 안배워서 생략하겠다.
# 실험해보기
위 yaml형식을 파일로 만들고 create해주면
kubectl create -f test-sf.yaml

이렇게 pod들이 만들어지게 된다.
사진으로는 담을수는 없지만 이름뿐 아니라 pod생성순서도 차례대로 0, 1, 2로 생기게 된다.
# podManagementPolicy
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: muzzi
spec:
selector:
matchLabels:
app: nginx-statefulset
serviceName: "nginx-statefulset-service"
podManagementPolicy: OrderedReady
replicas: 3
template:
metadata:
labels:
app: nginx-statefulset
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx-statefulset
image: nginx
ports:
- containerPort: 80
name: web
저기에 OrderedReady라고 값을 넣어주고 다시 statefulSet을 생성해보자
결과를 보면 이전과 다름이 없다.
만약 이 podManagementPolicy를 안적어준다면 기본값으로 OrderedReady로 적용되기 때문이다.
OrderedReady는 먼저 0번 파드가 생성되고 완성되고 나서 다음 1번 파드가 생성되게 된다.
이렇게 순서대로 생성되게 해주는게 이 값의 역할이다.
만약 이 곳에 Parallel을 적어준다면
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: muzzi
spec:
selector:
matchLabels:
app: nginx-statefulset
serviceName: "nginx-statefulset-service"
podManagementPolicy: Parallel
replicas: 3
template:
metadata:
labels:
app: nginx-statefulset
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx-statefulset
image: nginx
ports:
- containerPort: 80
name: webkubectl create -f test-sf.yaml
동시다발적으로 평행하게 컨테이너가 creating되게 된다.
OrderedReady값은 컨테이너가 순서가 중요할때 써먹으면되고 Parallel값은 컨테이너 생성 속도가 중요할떄 쓰면 된다.
# podManagementPolicy는 pod 생성에만 관여할까?
rolling Update에서도 관여한다.
예를들어 pod를 rolling update를 하게 된다면,
OrderedReady인경우는 마지막번부터 업데이트를 하게 된다.
사진으론 0,1,2가 있으니, 2번부터 1번, 0번 순으로 업데이트 되게 된다.
2번이 업데이트 완료되면 1번업데이트를 시작하는 방식이다.
직접해봤는데 사진으로 잡기 어려워서..
# statefulSet에서 replicas 수를 조절하게 된다면,
원래 세개의 파드가 있는데 두 개로 줄여보자.
kubectl scale statefulset muzzi --replicas=2
2번 pod부터 지워진다.
다시 그럼 다섯개로 늘려보자
kubectl scale statefulset muzzi --replicas=51번까지 있었으니 2,3,4번이 새로 생기게 된다.
이렇게 순서를 보장하면서 pod 생성, scale, rolling update를 보장하는게 statefulSet의 특징이다.