controller/ job
# 기본적인 pod 동작원리
kubectl run testpod --image centos:7 --command sleep5pod의 기본적인 특징이, pod안에 컨테이너가 제대로 안되면 계속 재시작을 시킴
liveness container는 이런걸 커스텀 할 수 있는것 같고..
기본적으로는 pod안에 컨테이너가 정상이아니면 계속 살려냄.
kubectl get pods -o wide --watch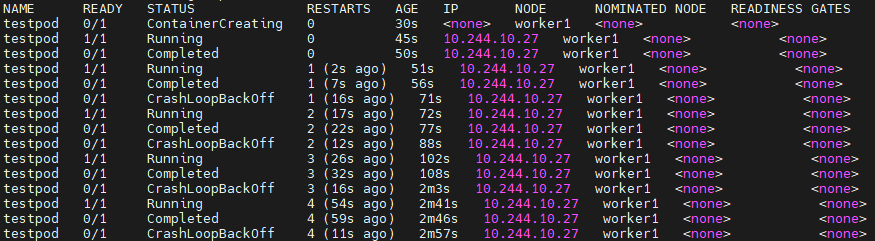
containerCreating으로 컨테이너가 생겨나고, running하다가 5초후에 sleep 5 커맨드가 끝나고 멈춰버린다.
안에있던 코드는 정상적으로 종료된거다. 때문에 completed가 뜨고 실행중인 컨테이너가 0/1로 바뀌는데,
이제 동작하는 컨테이너가 없으니 다시 이 컨테이너를 살려내고 다시 5초후 completed가 되고 또죽어버린다..
다시 crashLoopBackoff시간을 잡아먹고 계속 반복되는거다.
pod가 running중이 아니면 계속 살려내는 특징을 갖고 있음.
# job
이 컨트롤러는 이러한 pod의 특성에 반하는, 한번만 실행되면 되는 pod를 관리하는데 사용된다.
예를들어 로그를 전체적으로 어딧따가 보낸다거나, 백업을 진행한다거나 할때 쓰는 람다같은? 느낌인것같다.
후에 또 배우지만 이러한 작업의 주기를 컨트롤할수있는데 job이 종속적으로 있는 cronJob이다.
# job yaml
공식문서에 있는 job양식은 동작하지 않더라..ㅠㅠ
이미지가 perl? 이걸로 되어있는데 이미지 가져오는데 안되는거같음..
그래서 난 강의에있는 양식으로 할 예정이다.
apiVersion: batch/v1
kind: Job
metadata:
name: muzzi-good-job
spec:
template:
spec:
containers:
- name: centos-con
image: centos:7
command: ["bash"]
args:
- "-c"
- "echo 'hello muzzi'; sleep 10; echo 'muzzi bye'"
restartPolicy: Never
#backoffLimit: 4
++ 추가해서 강의에서는 apiVersion이 apps/v1인데, batch/v1으로 해야 제대로 컨테이너가 만들어짐.
# 암튼 만들어보자~
위에 yaml양식을 보면, args에 커맨드가 hello muzzi를 출력한후 10초 있다가 muzzi bye를 출력하고 끝난다.
이 작업이 실행중일때는 status가 running이다가 끝나면 status가 complete로 바뀔것이다.
kubectl create -f test-job.yaml
job이 성공적으로 만들어졌다.
pod상태를 볼까?
watch kubectl get pods -o wide

컨테이너가 만들어지고 있다. status와 ready를 잘 보자

ready에 동작중인 컨테이너가 1/1로 생겨났고, status를 보면 running상태가 되었다.
컨테이너가 잘 동작중이라는거다.

약 10초가 지나자 이후로는 ready가 0/1로 동작중인 컨테이너가 없는걸로 나오고, status가 completed로 바뀌었다.
그리고 이 포스팅 처음에서 설명했던 pod가 다시 컨테이너를 재시작시켜주지 않는다.
이게 job의 특징이다.
# 조금더 비교를 해보자.
강의와 설명만으로는 조금 애매해서 실제로 내멋대로 테스트를 해보겠다.
test-pod.yaml이라는 파일을 만들고 위에 job으로 생성한 pod와 동일한 기능을 하는 pod를 만들어보겠다.
apiVersion: v1
kind: Pod
metadata:
name: muzzi-good-pod
spec:
containers:
- name: centos-con
image: centos:7
command: ["bash"]
args:
- "-c"
- "echo 'hello muzzi'; sleep 10; echo 'muzzi bye'"이 파드는 위에 job에서 생성한 pod와 동일한 기능을 하는 pod이다.
이 pod와 아까 job을 동시에 같이 만들어보자.
kubectl create -f test-pod.yaml; kubectl create -f test-job.yaml
동시에 job과 pod를 yaml 형식파일로 create했다.
둘다 running상태로 시작을 했다.

10초이후로 지나서 둘다 ready가 0/1로 변하고, status는 completed가 되었다.
하지만 자세히 보면 일반 pod는 restart가 1로 변했다.

잠시후에 다시 muzzi-good-pod는 ready가 1/1로 변하고 status는 running이 되었다.
이 과정을 계속 반복하게 된다.
restart가 2로 된건 스크린샷 타이밍을 잘 못잡아서 그런거니 양해좀..
암튼 결론적으로 단독으로 만든 pod는 안에있는 컨테이너가 종료되고 아무것도 없으면 다시 그 컨테이너를 재실행 시켜주는 특징을 가지고 job으로 만든 pod는 한번만 정상적으로 실행되고 실행되는 컨테이너가 아무것도 없더라도 재시작시키지 않는다.
# yaml의 restartPolicy필드와 backoffLimit필드
얘는 pod안의 컨테이너가 실패했을경우, 재시작 시켜주는 기능을 제어하는 필드이다.
위에 예시에서는 pod안의 컨테이너가 정상적으로 종료된경우고
이번에 다룰건 컨테이너가 정상적으로 종료되지 않았을 경우를 얘기한다.
apiVersion: batch/v1
kind: Job
metadata:
name: muzzi-good-job
spec:
template:
spec:
containers:
- name: centos-con
image: centos:7
command: ["bashmuzzibabo"]
args:
- "-c"
- "echo 'hello muzzi'; sleep 10; echo 'muzzi bye'"
restartPolicy: OnFailure
backoffLimit: 3yaml형식에서 알 수 있는데,
restartPolicy필드는 두 가지가 있다.
- OnFailure : 실패할경우 재시작해주는데 저기보이는 backoffLimit필드의 값만큼 재시작해준다. backoffLimit은 OnFailure과 함께 써야한다.
- Never : 실패해도 컨테이너를 재시작시켜주지 않는다. 대신 pod를 새로만들어서 재시작해준다.
# OnFailure 실행해보기
위에 yaml 형식에서는 command 필드에 없는 커맨드를 쓰게 했고 이것때문에 컨테이너는 띄워지지 않을것이다.
restartPolicy에 Onfailure로 설정하고 backoffLimit을 3으로 해보고 저 job을 만들어보자.





pod가 만들어졌고 restart 횟수가 점점 높아지더니 3이 되고나서 몇초후에 이 pod는 사라져버렸다.
pod를 아예 삭제를 해버리는거다.
떄문에 이 로그를 보려고 해는데 삭제된 pod는 log나 describe를 쓸수가 없어서 describe job을 헀다.
kubectl describe jobs.batch muzzi-good-job
backoffLimitExceeded라고 횟수 다 찼다는 로그가 마지막이다.
# 그럼 Never일경우는 어떨까?
apiVersion: batch/v1
kind: Job
metadata:
name: muzzi-good-job
spec:
template:
spec:
containers:
- name: centos-con
image: centos:7
command: ["bashmuzzi hi"]
args:
- "-c"
- "echo 'hello muzzi'; sleep 10; echo 'muzzi bye'"
restartPolicy: Never
# backoffLimit: 3이렇게 실행을 해보겠다.
kubectl create -f test-job.yaml
얘는 container를 재시작해주는게아니라 아예 pod를 새로 만들어서 재시작해준다.
얘는 계속 무한정 만들어준다.
# restartPolicy가 Never일경우 횟수 제한 하기.
강의도 gpt도 이상하다..ㅡㅡ
Never일경우 무한정 pod를 만들어서 재시작시켜준다고했는데 이것까진 맞다. 근데 강의에선 completions로 제한할수 있다고하는데 실험해보니 안된다. 이 completions는 pod가 running이 끝나고 completed일경우 (성공할경우)에 몇 번 재시작시켜주냐는거고, 우리가 실험하는건 restartPolicy가 Never일경우 pod재생성 및 재시작 횟수를 제한하는거다.
고로 Never일경우도 backoffLimit으로 제한 할 수 있다.
apiVersion: batch/v1
kind: Job
metadata:
name: muzzi-good-job
spec:
# completions: 3
template:
spec:
containers:
- name: centos-con
image: centos:7
command: ["bashccc"]
args:
- "-c"
- "echo 'hello muzzi'; sleep 10; echo 'muzzi bye'"
restartPolicy: Never
backoffLimit: 3이렇게 yaml짜고 job을 만들어보면
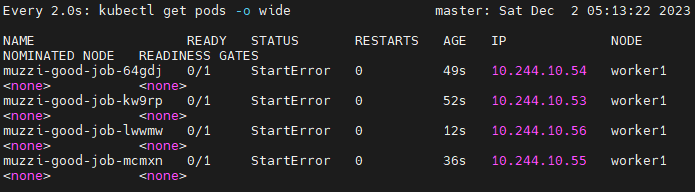
이렇게 네개까지의 pod를 만들어보고 job은 포기를 해버린다.
backoffLimit의 횟수제한으로 조절한거다.
그럼 왜 네개냐?
처음 pod생성되고 실패하고 한번, 두번째 pod만들고 한번, 세번째 pod만들고 한번, 네번쨰 만들고 restart 안함.
그래서 총 세번 restart를 헀고 파드는 네개가 만들어진거다.
# completions필드
얘는 파드가 completed가 되고 몇번 더 실행할거냐라는걸 설정해주는 필드이다.
apiVersion: batch/v1
kind: Job
metadata:
name: muzzi-good-job
spec:
completions: 3
template:
spec:
containers:
- name: centos-con
image: centos:7
command: ["bash"]
args:
- "-c"
- "echo 'hello muzzi'; sleep 10; echo 'muzzi bye'"
restartPolicy: Neverjob의 spec에서 completions으로 정의할수 있다.
이렇게 job을 만들어보면,

하나 실행되고

첫번째꺼가 completed되면 두번째꺼 만들어지고..
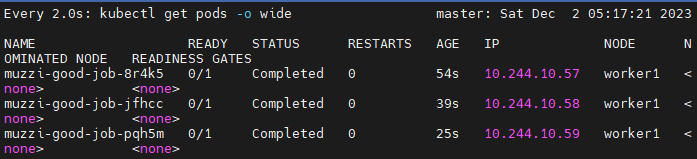
이렇게 세번까지 completed가 된 후, 멈춰버린다
위에서 일부러 에러났던건 status가 startError였고 이번엔 완료된 completed다.
# parellelism 필드
위에서 completions에서 실험했을경우 하나씩 실행되고 이전 pod가 completed가 되면 다시 새로운 pod를 만들어줬다.
근데 얘는 한번에 몇개까지 pod를 만들건지 설정하는 필드이다.
apiVersion: batch/v1
kind: Job
metadata:
name: muzzi-good-job
spec:
completions: 3
parallelism: 3
template:
spec:
containers:
- name: centos-con
image: centos:7
command: ["bash"]
args:
- "-c"
- "echo 'hello muzzi'; sleep 10; echo 'muzzi bye'"
restartPolicy: Never
# backoffLimit: 3
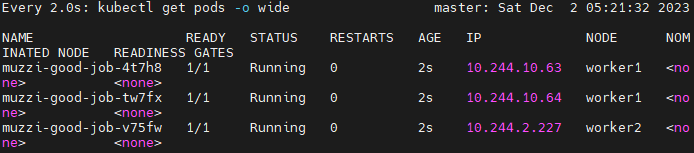
세 개 모두 running으로 실행되다가

모두 completed가 되었다.
# activeDeadlineSeconds
컨테이너가 동작이 몇초내로 안끝나면 강제로 completed로 변환해버리겠다는 필드이다.
apiVersion: batch/v1
kind: Job
metadata:
name: muzzi-good-job
spec:
# completions: 3
# parallelism: 3
activeDeadlineSeconds: 5
template:
spec:
containers:
- name: centos-con
image: centos:7
command: ["bash"]
args:
- "-c"
- "echo 'hello muzzi'; sleep 10; echo 'muzzi bye'"
restartPolicy: Never
# backoffLimit: 3위 yaml 형식에서 컨테이너에 10초후에 completed가 되는 설정을 해놨다.
근데 activeDeadlineSeconds를 5초로 설정했기때문에 저 컨테이너는 저 커맨드들이 다 끝나지 않았더라도 강제로 completed가 될것이다.
실행해보면,

이렇게 5초부터 갑자기 terminating이 되었다.

그리고 job의 pod는 삭제된다.
그리고 job의 describe를 보면

이렇단다.
근데 강의나 gpt나 pod가 completed상태가 된다고 하는데..
위에서 일반적인 job을 실험해본 바로는 completed가 되고 해당 pod가 삭제되지않는다. 로그보고 할떄 유용할텐데..
근데 방금 activeDeadlineSeconds를 설정해서 강제로 completed가 되어버린 pod는 바로 종료되고 삭제되어버리고 job만 남아버린다.
completed인상태로 그냥 남아있을줄 알았는데..
내가 아직 개념이 부족한가 아니면 강의나 gpt가 설명을 잘 못하는건가.. 모르겄다